
Contextual Data Point Extraction
Extract pin-pointed data from tables - and key descriptions
Advanced Capabilities
Powerful Search
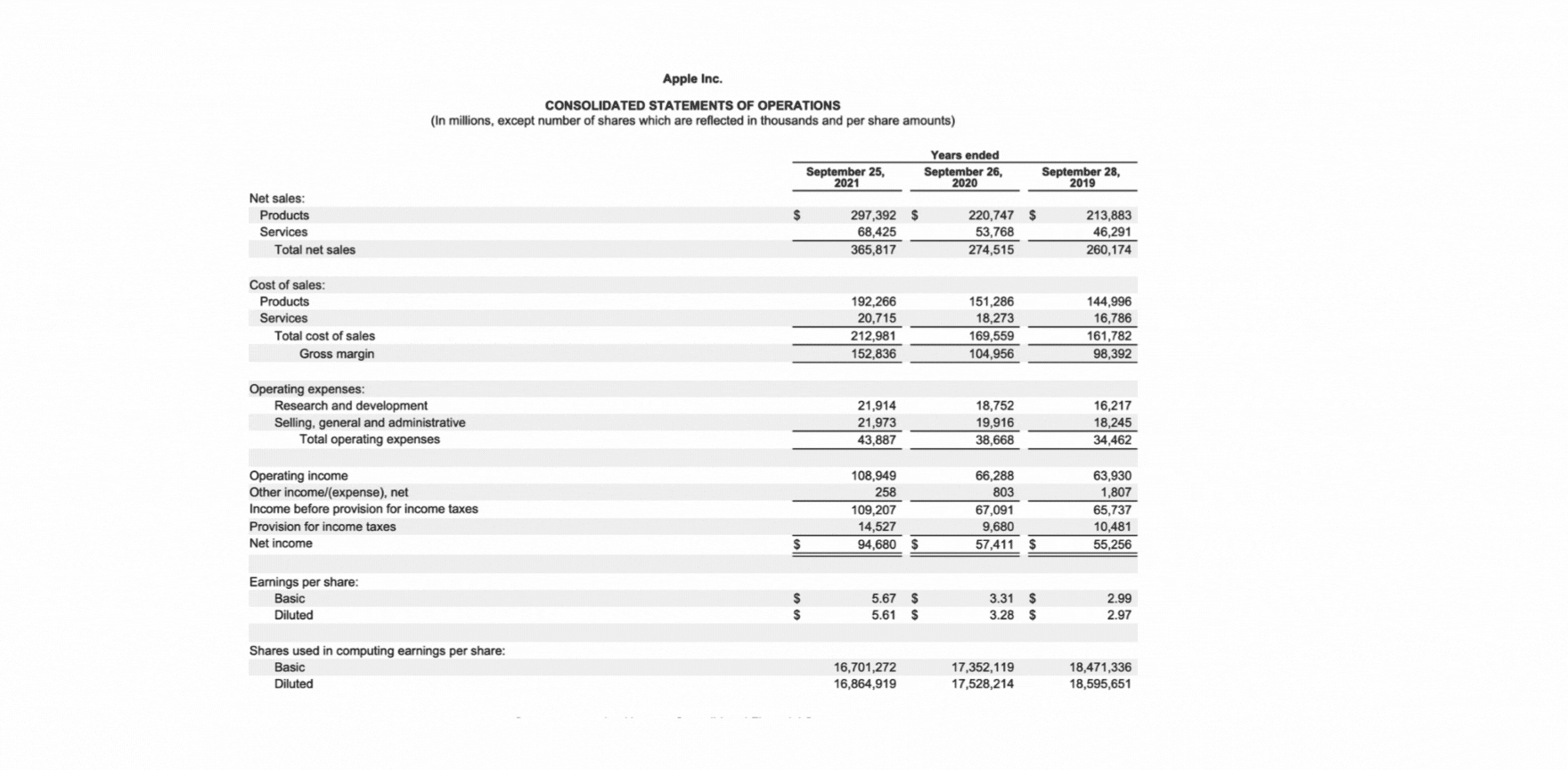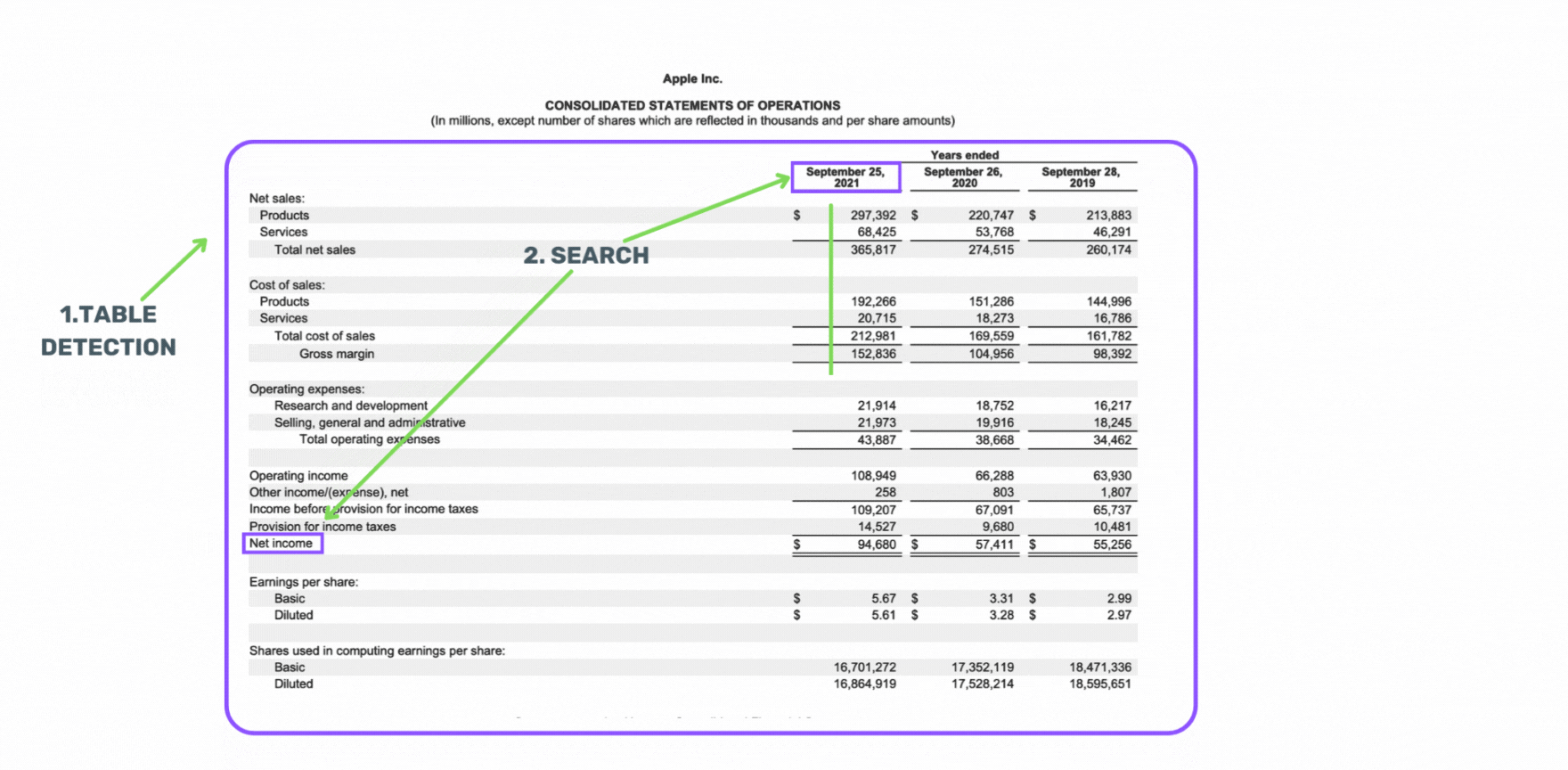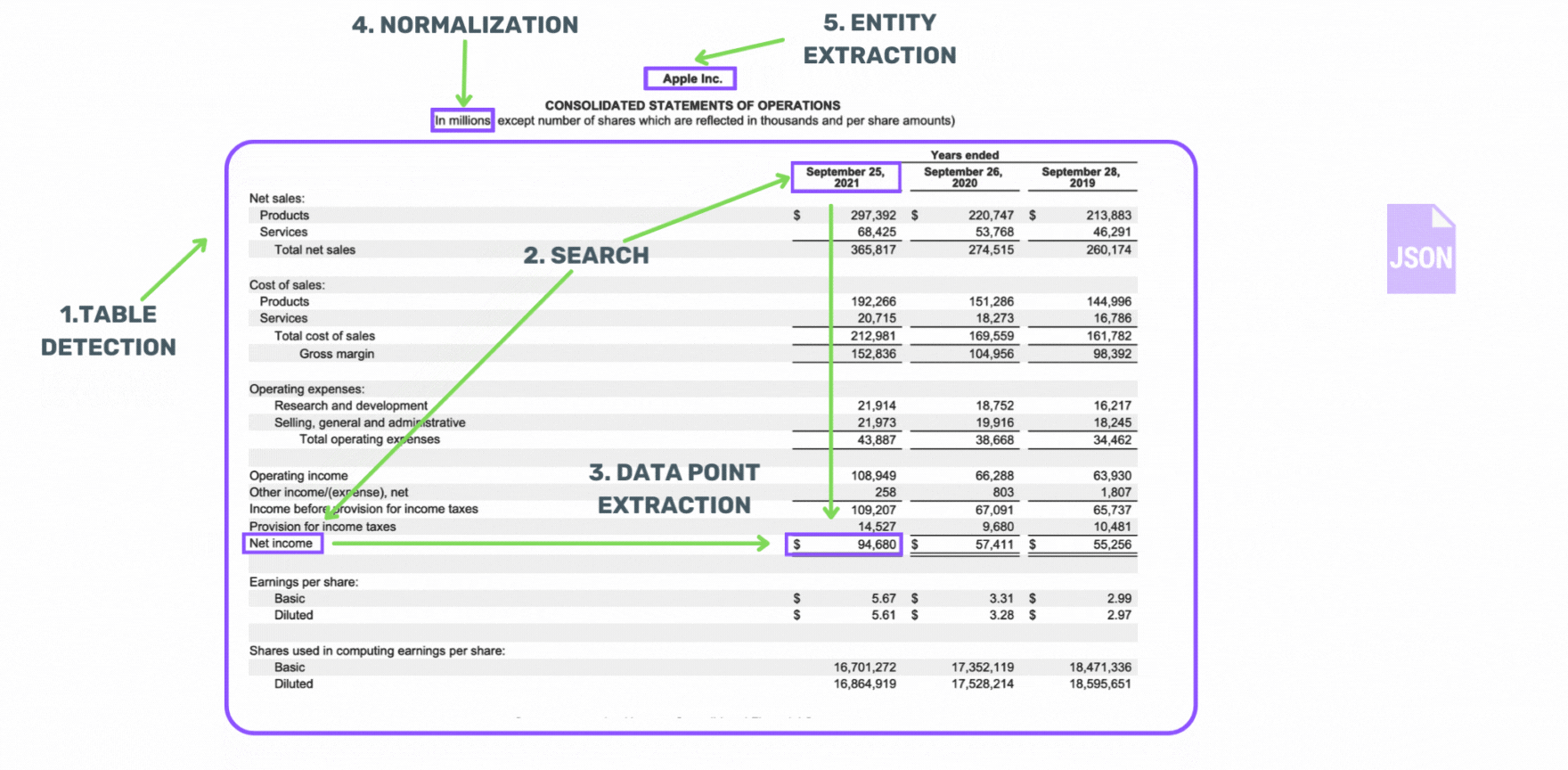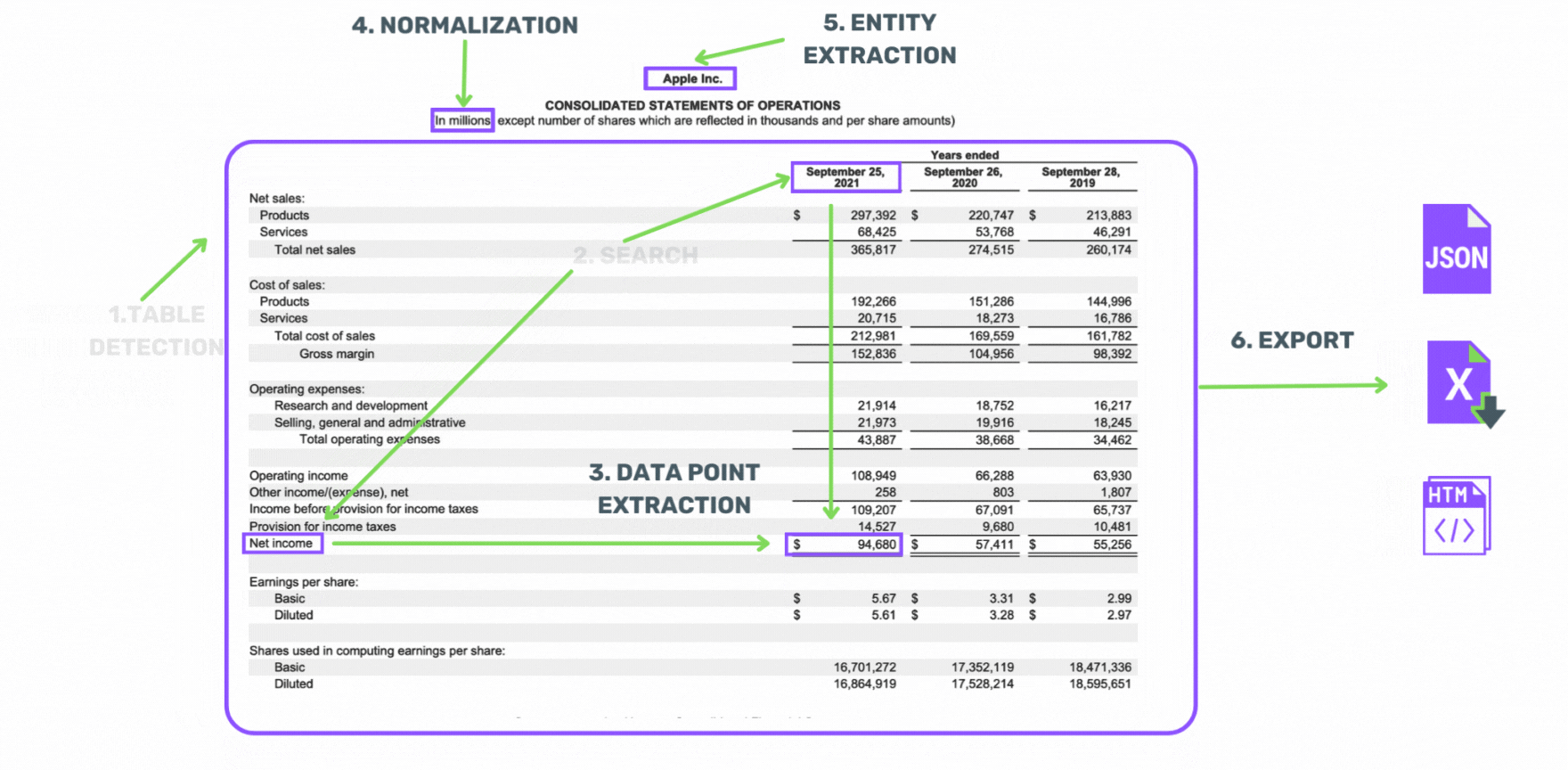
Pulls out data points from one or thousands of documents within a few seconds. Searches are targeted at numerical data within tables. It can also find and extract text in paragraphs and headers (like a Google search).


Normalization & Entity Extraction
Find descriptors outside the table such as the currency, units and entity to which a table refers.
Human In The Loop
Easily review the data in the original document with a quick preview for validation or modification by humans.


Table Extraction
Extract all tables from one, or many, documents all at once. Then, easily export them in Excel, JSON or HTML.
Zanran - Overview

Flexible Deployment

On-Premises Deployment

Hybrid Deployment

Cloud Deployment
Zanran's full capabilities are easily integrated with your system through Zanran's APIs.
Platform Benefits
Versatile Platform
A flexible platform allowing you to process many different use cases around documents, using a single technology. New modules can easily be added over time to accommodate new requirements - you are not locked into one solution.
Document & Industry Agnostic
The platform can process a whole range of different types of documents whether they're scanned documents or native PDF ones. It can accommodate different industry-specific documents such as Fund Reports, SEC Form 10-Ks, Annual Reports, Brokers Reports, Life Science papers, etc.
AI & Language Agnostic
The Zanran platform enables you to plug in the latest Natural Langage Processing (NLP) and Computer Vision deep learner models. You will not be left with old technology in this rapidly changing AI world.
The core layout software (which identifies tables, paragraphs, etc) is vision-based and independent of language. It will work equally well with documents in French, Russian or Greek.. For search, the platform can accommodate any language, expanding the range of use cases.
Scalable Technology
Scale up processes from a few documents to millions of documents without performance degradation.
Blue Chip Companies, Big 4 Accounting Firms and Investment Funds
are amongst our customers who are now able to extract huge volumes of data automatically, with very little human intervention.
Solutions
FOR INVESTMENT FUNDS - LPs and GPs
FOR AUDIT & ACCOUNTING
FOR TECHNOLOGY LEADERS
FOR DATA
PROVIDERS




The Zanran platform will help speed up the process of extracting financial data from reports or sets of accounts. You get the results same day, not next week.
Run on-prem it will also improve security and confidentiality.
Example: as an LP you receive Private Equity quarterly reports - as PDFs. You want to extract the portfolio companies’ performance data – speak to Zanran for your PE portfolio monitoring software.
Example: as a GP you receive management accounts from your companies. Speak to Zanran about extracting the financial data and sending it to your database.
Request demo
To schedule a product demo with one of our product consultants, please fill in your contact details
Zanran Ltd, 4 Highbury Place
London, N5 1QZ, UK